 ナノトイラボ
ナノトイラボ 

今回は、PythonのOpenCVやアフィン変換を用いて、イタリック体の文字の縦画を自動的に垂直に補正する方法を解説していきます。
ローマン体を補正する「slant補正」に関しては次の記事が参考になると思います。
参考:【Python・OpenCV】傾斜文字画像の画角を自動で補正をする方法(slant補正)
参考:【Python・OpenCV】斜体文字画像の画角を補正する方法(アフィン変換・slant補正・傾斜補正)
目的とサンプル
本記事の目的は、イタリック体(左のように文字が斜めに傾いていること)文字画像の縦画を垂直に自動的に補正することです。
下の表は、元画像に対して、角度推定を行い、文字画像を補正した時のサンプルです。
各画像に対して各々の角度を自動推定しています。機械学習において、文字の正規化は文字認識率の向上につながることが考えられています。
| 元画像 | 補正後 | 補正角度 |
|---|---|---|
 |  | 10度 |
 |  | 9度 |
 | | 0度 |
 |  | 10度 |
 |  | 12度 |
 |  | 12度 |
文字の角度推定の方法
参考論文:傾斜文字認識のための正規化方法
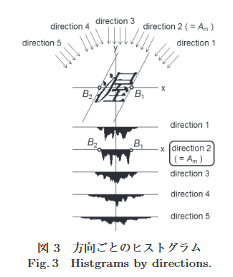
イタリック体の文字の自動補正には、参考にした論文での手法がそのまま使えます。
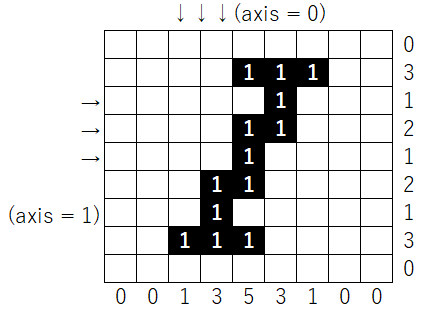
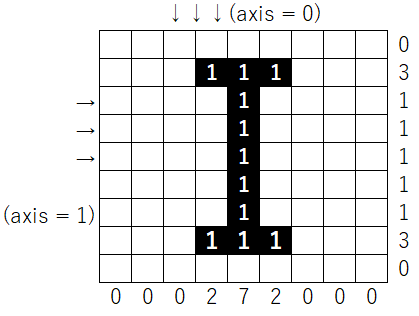
まずは、方向ごとのヒストグラムを作成します。その後、縦方向に対する投影値の2乗の値の合計と、横幅との比が最も大きくなる時の角度を文字の補正角度とします。具体的な例は下のようになります。
どちらの画像もある角度で傾けた後の画像だと思ってください。
実装
ここからは具体的にサンプルコードを紹介していきます。
今回用いた画像ファイルを置いておきます。画像のみで安全ですよ。怖い場合には各自で文字画像を準備してくださいね。
画像の傾き補正
1 2 3 4 5 6 7 8 9 10 11 | # imageをthetaの角度で傾ける def Affine(image, theta): # 画像サイズを取得 h, w = image.shape[:2] src = np.array([[0.0, 0.0],[0.0, 1.0],[1.0, 0.0]], np.float32) dest = np.array([[0.0, 0.0],[np.sin(theta), 1.0],[1.0, 0.0]], np.float32) # アフィン変換を行う affine = cv2.getAffineTransform(src, dest) return cv2.warpAffine(image, affine, (w, h), borderMode=cv2.BORDER_CONSTANT, borderValue=255) |
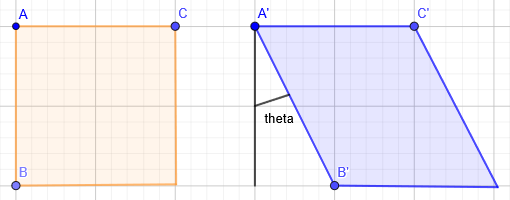
ここでの「src」と「dest」の決定方法を説明します。
「src」では、変換前の3つの座標(A, B, C)を設定します。そして、イタリック補正を行うときの変換後の座標を(A’, B’, C’)とすると次のようになります。
・ A(0, 0) → A'(0, 0)
・ B(0, 1) → B'(sin(theta), 1)
・ C(1, 0) → C'(1, 1)
比を求める
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | def cut_img(img): # 投影値を求めるためのimg_copyを作成 img_copy = img.copy() # 大津の二値化 _, img_copy = cv2.threshold(img_copy, 0, 255, cv2.THRESH_OTSU) for h in range(img_copy.shape[0]): for w in range(img_copy.shape[1]): # 黒画素ならば「1」を、白画素ならば「0」を割り当てる if img_copy[h][w] == 0: img_copy[h][w] = 1 elif img_copy[h][w] == 255: img_copy[h][w] = 0 # 縦軸の黒画素の数を数える x_dot = np.sum(img_copy, axis = 0) # 横軸の黒画素の数を数える y_dot = np.sum(img_copy, axis = 1) # 黒画素がある最小と最大のインデックス番号を取得 x_min, x_max = np.min(np.where(x_dot != 0)), np.max(np.where(x_dot != 0)) y_min, y_max = np.min(np.where(y_dot != 0)), np.max(np.where(y_dot != 0)) # 縦軸に対する投影値の2乗の合計を求める Sum = sum([x_i ** 2 for x_i in x_dot]) # 求めた比と、文字の書かれた範囲のみを返す(前後左右1ピクセル多く) return Sum / (x_max - x_min + 1), img[y_min - 1 : y_max + 1, x_min - 1 : x_max + 1] |
この関数では、ある角度で補正が行われた後の画像を受け取り、その画像に対する比と必要な部分を切り取った画像を返り値としています。
比の求め方に関してはすでに解説した通りです。
必要な部分の切り取り方法は、下記の画像の様に、黒画素が存在する最小と最大のインデックス番号をx軸とy軸でそれぞれ取得します。
ex)np.min(np.where(x_dot != 0))==2, np.max(np.where(x_dot != 0))==6
メイン関数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | import cv2 import numpy as np import glob # google colab上で画像を表示する用 from google.colab.patches import cv2_imshow if __name__ == "__main__": # 「characters_Italic/」の中にあるファイルパスをすべて取得 Files = glob.glob("characters_Italic/*") for File in Files: ans_ratio = 0 image = cv2.imread(File, 0) H, W = image.shape[:2] cv2_imshow(image) # 画像を傾けると一部がはみ出てしまうため余白を追加 image = cv2.copyMakeBorder(image, H, H, H, H, cv2.BORDER_CONSTANT, value=255) #cv2_imshow(image) for theta in range(0, 16): Affine_img = Affine(image, theta * np.pi / 180) #cv2_imshow(Affine_img) # 画像の中心を取得 center_y, center_x = map(int, [Affine_img.shape[0] / 2, Affine_img.shape[1] / 2]) #cv2_imshow(Affine_img[center_y - H : center_y + H, center_x - W : center_x + W]) ratio, cutterd_img = cut_img(Affine_img[center_y - H : center_y + H, center_x - W : center_x + W]) # この角度の時の比がより大きければ if ratio > ans_ratio: ans_ratio = ratio ans_theta = theta ans_cutted_img = cutterd_img print("theta :", ans_theta) cv2_imshow(ans_cutted_img) print("================") |
全体のコード
最後にコメントなしの全体のコードを載せます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 | import cv2 import numpy as np import glob from google.colab.patches import cv2_imshow def Affine(image, theta): h, w = image.shape[:2] src = np.array([[0.0, 0.0],[0.0, 1.0],[1.0, 0.0]], np.float32) dest = np.array([[0.0, 0.0],[np.sin(theta), 1.0],[1.0, 0.0]], np.float32) affine = cv2.getAffineTransform(src, dest) return cv2.warpAffine(image, affine, (w, h), borderMode=cv2.BORDER_CONSTANT, borderValue=255) def cut_img(img): img_copy = img.copy() _, img_copy = cv2.threshold(img_copy, 0, 255, cv2.THRESH_OTSU) for h in range(img_copy.shape[0]): for w in range(img_copy.shape[1]): if img_copy[h][w] == 0: img_copy[h][w] = 1 elif img_copy[h][w] == 255: img_copy[h][w] = 0 x_dot = np.sum(img_copy, axis = 0) y_dot = np.sum(img_copy, axis = 1) x_min, x_max = np.min(np.where(x_dot != 0)), np.max(np.where(x_dot != 0)) y_min, y_max = np.min(np.where(y_dot != 0)), np.max(np.where(y_dot != 0)) Sum = sum([x_i ** 2 for x_i in x_dot]) return Sum / (x_max - x_min + 1), img[y_min - 1 : y_max + 1, x_min - 1 : x_max + 1] if __name__ == "__main__": Files = glob.glob("characters_Italic/*") for File in Files: ans_ratio = 0 image = cv2.imread(File, 0) H, W = image.shape[:2] cv2_imshow(image) image = cv2.copyMakeBorder(image, H, H, H, H, cv2.BORDER_CONSTANT, value=255) #cv2_imshow(image) for theta in range(0, 16): Affine_img = Affine(image, theta * np.pi / 180) #cv2_imshow(Affine_img) center_y, center_x = map(int, [Affine_img.shape[0] / 2, Affine_img.shape[1] / 2]) #cv2_imshow(Affine_img[center_y - H : center_y + H, center_x - W : center_x + W]) ratio, cutterd_img = cut_img(Affine_img[center_y - H : center_y + H, center_x - W : center_x + W]) if ratio > ans_ratio: ans_ratio = ratio ans_theta = theta ans_cutted_img = cutterd_img print("theta :", ans_theta) cv2_imshow(ans_cutted_img) print("================") |
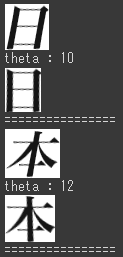
出力結果
結果についてです。
最初の1枚目が元画像で、2枚目が補正後の画像です。また、「theta」と書かれた2行目が、画像を傾けた実際の角度です。
この結果を見ると、文字の縦画が垂直に補正されており、目的通りイタリック体の補正ができていることが分かります。
まとめ
今回は、イタリック体で書かれた文字画像の画角をアフィン変換を用いて自動補正する方法を記述しました。
過去の記事では、ローマン体での自動補正を行う「slant補正」ついても解説しています。よろしければそちらも参考にしてみてください。
参考:【Python・OpenCV】傾斜文字画像の画角を自動で補正をする方法(slant補正)
参考:【Python・OpenCV】斜体文字画像の画角を補正する方法(アフィン変換・slant補正・Italic補正)
こちらで紹介しているスクールは、すべて無料期間がある優良なスクールのみで、特徴を明確にし、読者のニーズに絞って丁寧に解説しました。初めての一歩として、無料説明会に参加してみてください。

パソコン操作にお困りではありませんか?
ExcelやWordなど、基本的なソフトの使い方がいまいちわからないという方には、「PCHack」という講座をオススメしています。スクールの中でもコストパフォーマンスに優れ、オンラインなのでどこでも好きな時間に学習できます。
3万円ほどでPC初心者を脱出したい方は参考にしてください。
【PC初心者必見!】パソコンの勉強方法が分からないならPCHack講座がオススメ!


