 ナノトイラボ
ナノトイラボ 

今回は、PythonのOpenCVを用いて、文字画像の角度推定を行い、画角を自動的に補正する方法を解説していきます。この補正のことを「slant補正」といいます。
過去の記事では、 slant補正以外にも、イタリック体に対応する傾斜補正の方法についても解説しています。よろしければそちらも参考にしてみてください。
関連:【Python・OpenCV】斜体文字画像の画角を補正する方法(アフィン変換・slant補正・傾斜補正)
こちらで紹介しているスクールは、すべて無料期間がある優良なスクールのみで、特徴を明確にし、読者のニーズに絞って丁寧に解説しました。初めての一歩として、無料説明会に参加してみてください。

サンプル
元画像に対して、角度推定を行い、文字画像を補正した時のサンプルです。
各画像に対して各々の角度を自動推定しています。文字として「美しい」かどうかは疑問が残りますが、機械学習において、文字の正規化は文字認識率の向上につながることが考えられています。
| 元画像 | 出力結果 | 補正角度 |
|---|---|---|
 |  | 15度 |
 | | 0度 |
 |  | 3度 |
 | | 0度 |
 |  | 10度 |
 |  | 11度 |
文字の角度推定の方法
参考論文:傾斜文字認識のための正規化方法
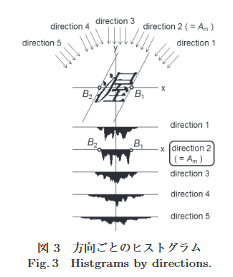
こちらの論文での文字の角度補正の方法を参考にアレンジしました。
文字の推定方法は、上の画像のように、方向ごとのヒストグラムを作成します。画像では、横画がまっすぐで、縦画が傾いています。しかし、日本人が書く文字は、次の画像のように右肩上がりの文字のため、横画に傾きがあります。
ex)漢字の「一」

そのため、水平方向に対する投影ヒストグラムを作成し、投影値の2乗の合計と、高さとの比が最も大きくなる時の角度を文字の補正角度とします。具体的な例は下のようになります。
比 = (各行の投影値の2乗の合計) / (文字の高さの幅)
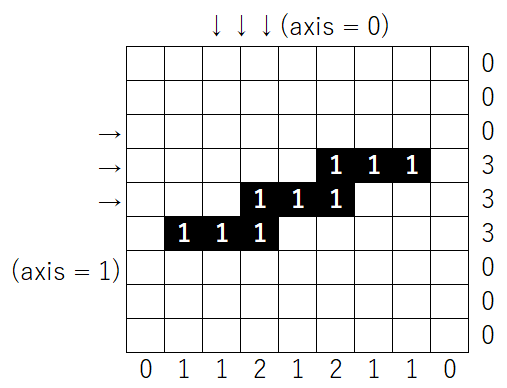
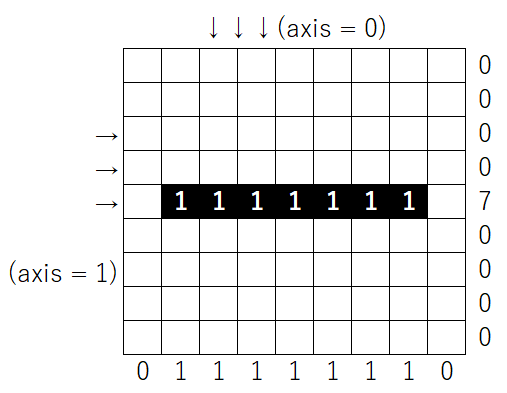
各画像に対して求められた比は「9」と「49」でした。
左側の画像に対して、右側の方が比の値が大きいため、この時に補正した角度を暫定の補正角度とします。
角度のレンジは0度から15度とし、一連の処理を繰り返すことで、最も比の値が大きかった角度を最終的な補正角度と設定します。このような処理を「slant補正」といいます。
実装
ここからは具体的にサンプルコードを紹介していきます。
今回用いた画像ファイルを置いておきます。画像のみで安全ですよ。
画像の傾き補正
1 2 3 4 5 6 7 8 9 10 | # imageをthetaの角度で傾ける def Affine_slant(image, theta): h, w = image.shape[:2] src = np.array([[0.0, 0.0],[0.0, 1.0],[1.0, 0.0]], np.float32) dest = np.array([[0.0, 0.0],[0.0, 1.0],[1.0, np.tan(theta)]], np.float32) affine = cv2.getAffineTransform(src, dest) # 角度thetaで傾けた時の画像を返す return cv2.warpAffine(image, affine, (w, h), borderMode=cv2.BORDER_CONSTANT, borderValue=255) |
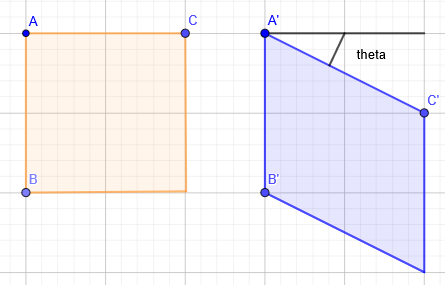
文字を傾けるためには、画像全体を画像内のある座標を(x, y)、変換後の座標を(x’, y’)としたときに、以下の行列で変換する必要があります。
$$\begin{bmatrix}x’ \\y’ \\ 1 \end {bmatrix}=\begin{bmatrix}1 &0 &0\\\tan\theta &1 &0\\0 &0 &1\end{bmatrix}\begin{bmatrix}x \\y\\ 1 \end{bmatrix}$$
プログラム中の「src」と「dest」の決定方法を説明します。
「src」では、変換前の3つの座標(A, B, C)を設定します。そして、slant補正を行う場合での変換後の座標を「dest」(A’, B’, C’)とすると次のようになります。
・ A(0, 0) → A'(0, 0)
・ B(0, 1) → B'(0, 1)
・ C(1, 0) → C'(1, tan(theta))
比を求める
関数名いかれてますが気にしないでください。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | def cut_img(img): img_copy = img.copy() # 大津の二値化 _, img_copy = cv2.threshold(img_copy, 0, 255, cv2.THRESH_OTSU) for h in range(img_copy.shape[0]): for w in range(img_copy.shape[1]): # 黒ならば「1」、白ならば「0」を割り当てる if img_copy[h][w] == 0: img_copy[h][w] = 1 elif img_copy[h][w] == 255: img_copy[h][w] = 0 # 縦軸で見た時の黒の個数を数える x_dot = np.sum(img_copy, axis = 0) # 横軸で見た時の黒の個数を数える y_dot = np.sum(img_copy, axis = 1) # 黒がある最小・最大のインデックス番号を取得する x_min, x_max = np.min(np.where(x_dot != 0)), np.max(np.where(x_dot != 0)) y_min, y_max = np.min(np.where(y_dot != 0)), np.max(np.where(y_dot != 0)) # 投影値の2乗の合計 Sum = sum([y_i ** 2 for y_i in y_dot]) # 比と、黒のある部分だけの画像を切り取る return Sum / (y_max - y_min + 1), img[y_min - 1 : y_max + 1, x_min - 1 : x_max + 1] |
画像の切り取りで行っていることは、配列「x_dot」と「y_dot」に0以外の何かしらの値だった場合に文字部分と判断するようにしています。
下の画像の場合、np.min(np.where(x_dot != 0)) == 1となります。
メイン関数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | if __name__ == "__main__": # 「characters/」の中にあるファイルパスをすべて取得 Files = glob.glob("characters/*") for File in Files: ans_ratio = 0 # グレースケールで画像を読みとる image = cv2.imread(File, 0) H, W = image.shape[:2] cv2_imshow(image) # 画像に白の余白を追加 image = cv2.copyMakeBorder(image, H, H, H, H, cv2.BORDER_CONSTANT, value=255) #cv2_imshow(image) for theta in range(0, 16): Affine_img = Affine_slant(image, theta * np.pi / 180) #cv2_imshow(Affine_img) # 余白追加した画像の中心座標を取得 center_y, center_x = map(int, [Affine_img.shape[0] / 2, Affine_img.shape[1] / 2]) #cv2_imshow(Affine_img[center_y - H : center_y + H, center_x - W : center_x + W]) # 角度「theta」の時の比と切り取られた画像を受け取る ratio, cutted_img = cut_img(Affine_img[center_y - H : center_y + H, center_x - W : center_x + W]) # 角度「theta」の時の比が、暫定1位の比よりも大きかったら if ratio > ans_ratio: ans_ratio = ratio ans_theta = theta ans_cutted_img = cutted_img print("theta :", ans_theta) cv2_imshow(ans_cutted_img) print("================") |
全体のコード
最後にコメントなしの全体のコードを載せます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | import cv2 import numpy as np import glob from google.colab.patches import cv2_imshow def Affine_slant(image, theta): h, w = image.shape[:2] src = np.array([[0.0, 0.0],[0.0, 1.0],[1.0, 0.0]], np.float32) dest = np.array([[0.0, 0.0],[0.0, 1.0],[1.0, np.tan(theta)]], np.float32) affine = cv2.getAffineTransform(src, dest) return cv2.warpAffine(image, affine, (w, h), borderMode=cv2.BORDER_CONSTANT, borderValue=255) def cut_img(img): img_copy = img.copy() _, img_copy = cv2.threshold(img_copy, 0, 255, cv2.THRESH_OTSU) for h in range(img_copy.shape[0]): for w in range(img_copy.shape[1]): if img_copy[h][w] == 0: img_copy[h][w] = 1 elif img_copy[h][w] == 255: img_copy[h][w] = 0 x_dot = np.sum(img_copy, axis = 0) y_dot = np.sum(img_copy, axis = 1) x_min, x_max = np.min(np.where(x_dot != 0)), np.max(np.where(x_dot != 0)) y_min, y_max = np.min(np.where(y_dot != 0)), np.max(np.where(y_dot != 0)) Sum = sum([y_i ** 2 for y_i in y_dot]) return Sum / (y_max - y_min + 1), img[y_min - 1 : y_max + 1, x_min - 1 : x_max + 1] if __name__ == "__main__": Files = glob.glob("characters/*") for File in Files: ans_ratio = 0 image = cv2.imread(File, 0) H, W = image.shape[:2] cv2_imshow(image) image = cv2.copyMakeBorder(image, H, H, H, H, cv2.BORDER_CONSTANT, value=255) #cv2_imshow(image) for theta in range(0, 16): Affine_img = Affine_slant(image, theta * np.pi / 180) #cv2_imshow(Affine_img) center_y, center_x = map(int, [Affine_img.shape[0] / 2, Affine_img.shape[1] / 2]) #cv2_imshow(Affine_img[center_y - H : center_y + H, center_x - W : center_x + W]) ratio, cutted_img = cut_img(Affine_img[center_y - H : center_y + H, center_x - W : center_x + W]) if ratio > ans_ratio: ans_ratio = ratio ans_theta = theta ans_cutted_img = cutted_img print("theta :", ans_theta) cv2_imshow(ans_cutted_img) print("================") |
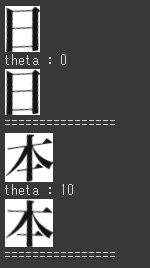
出力結果
結果はこんな感じです。
画像の1枚目が元画像で、2枚目は、slant補正を行った画像です。「theta」には、slant補正が行われたときの角度を示しています。
文字の横画が水平になっているのが分かると思います。
まとめ
最後までお読みいただきありがとうございます。
今回は、傾斜文字の画角をアフィン変換を用いて自動補正する方法を記述しました。
過去の記事では、slant補正以外にも、イタリック体に対応する傾斜補正の方法についても解説しています。よろしければそちらも参考にしてみてください。
参考:【Python・OpenCV】斜体文字画像の画角を補正する方法(アフィン変換・slant補正・傾斜補正)
こちらで紹介しているスクールは、すべて無料期間がある優良なスクールのみで、特徴を明確にし、読者のニーズに絞って丁寧に解説しました。初めての一歩として、無料説明会に参加してみてください。
パソコン操作にお困りではありませんか?
ExcelやWordなど、基本的なソフトの使い方がいまいちわからないという方には、「PCHack」という講座をオススメしています。スクールの中でもコストパフォーマンスに優れ、オンラインなのでどこでも好きな時間に学習できます。
3万円ほどでPC初心者を脱出したい方は参考にしてください。
【PC初心者必見!】パソコンの勉強方法が分からないならPCHack講座がオススメ!


