 ナノトイラボ
ナノトイラボ 

今回は最近流行りのスプレイピングについてやっていきます。
スプレイピングができれば、あなたはプログラミングについて深く知ることができます。私も最近学び始めて、スプレイピングの凄さに驚きました。
今回はWebページのタイトルを取り出す方法について解説します。
Webページからテキストや画像を抽出する技術です。
今回はこちらのスプレイピングをPythonを使って行います。
無料オンライン相談を活用しよう!
Pythonというプログラミング言語は機械学習の人気の高まりなどもあり、様々なスクールが無料説明会を開催しています。
その中でも「Freeks(フリークス)|業界初!10,780円のサブスク型プログラミングスクール」がオススメです。Pythonを効率よく学びたいという方はまずは適性を知るためにも無料説明会を利用しましょう。
コンテンツ
HTMLタグ
まず、スプレイピングをやる上でHTMLを理解しなければなりません!!
下記は私たちのサイト【Python】画像内でクリックした箇所のRBG・HSVの値を取得しExcelに出力する方法のHTMLの一部となっています。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | <!doctype html> <html lang="ja"> <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="HandheldFriendly" content="True"> <meta name="MobileOptimized" content="320"> <meta name="viewport" content="width=device-width, initial-scale=1, viewport-fit=cover"/> <meta name="msapplication-TileColor" content="#3fc6db"> <meta name="theme-color" content="#3fc6db"> <link rel="pingback" href="https://nano-toy-lab.com/xmlrpc.php"> <title>【Python】画像内でクリックした箇所のRBG・HSVの値を取得しExcelに出力する方法 | ナノトイラボ</title> <meta name='robots' content='max-image-preview:large' /> <link rel='dns-prefetch' href='//www.google.com' /> <link rel='dns-prefetch' href='//www.googletagmanager.com' /> <link rel='dns-prefetch' href='//fonts.googleapis.com' /> <link rel='dns-prefetch' href='//use.fontawesome.com' /> <link rel='dns-prefetch' href='//s.w.org' /> <link rel='dns-prefetch' href='//pagead2.googlesyndication.com' /> <link rel="alternate" type="application/rss+xml" title="ナノトイラボ » フィード" href="https://nano-toy-lab.com/feed/" /> <link rel="alternate" type="application/rss+xml" title="ナノトイラボ » コメントフィード" href="https://nano-toy-lab.com/comments/feed/" /> |
上のコード見ても、何書いてあるのか分からないよぉー
HTMLで重要なのはタグの意味と使い方です。
よく使うタグを列挙してみました!
| タグ | 意味 |
|---|---|
| <html> | HTMLのルート要素 |
| <head> | ヘッダ(メタデータ) |
| <title> | 文書のタイトル |
| <base> | 相対的な基準となるURL |
| <h1>~<h6> | 見出し |
| <section> | 文書内セクション |
| <a> | リンク |
| <div> | 範囲指定 |
| <p> | 段落 |
スクレイピングに便利なライブラリー
こちらでは、スプレイピングに便利なPythonライブラリを紹介します。実際に下の実行例でも使われています。
Requestsは、PythonのHTTP通信ライブラリです。
Requestsを使うとWebサイトの情報取得や画像の収集などを簡単に行えます。
Requests ライブラリは、他のライブラリと組み合わせて使用できます。
BeautifulSoup4は、HTMLやXMLからデータを取得・解析するためのライブラリーです。
取得したWebページから必要な要素やテキストを取り出すのに使います。
「Beautiful Soup」を用いることで、Webサイト内の情報を解析して必要なものだけを抜き出すことができます。
また、モジュールの一つである「BytesIO」や「Pillow」と組み合わせて、Webサイト上の画像URLをもとに、画像ファイルを取得することもできます。
HTMLファイルからタイトルを取り出す
今回はWebページのタイトルを取り出すために、下のサイトを使用します。
 【Python】画像内でクリックした箇所のRBG・HSVの値を取得しExcelに出力する方法
【Python】画像内でクリックした箇所のRBG・HSVの値を取得しExcelに出力する方法 HTMLファイルを保存
まず、HTMLファイルを保存します。
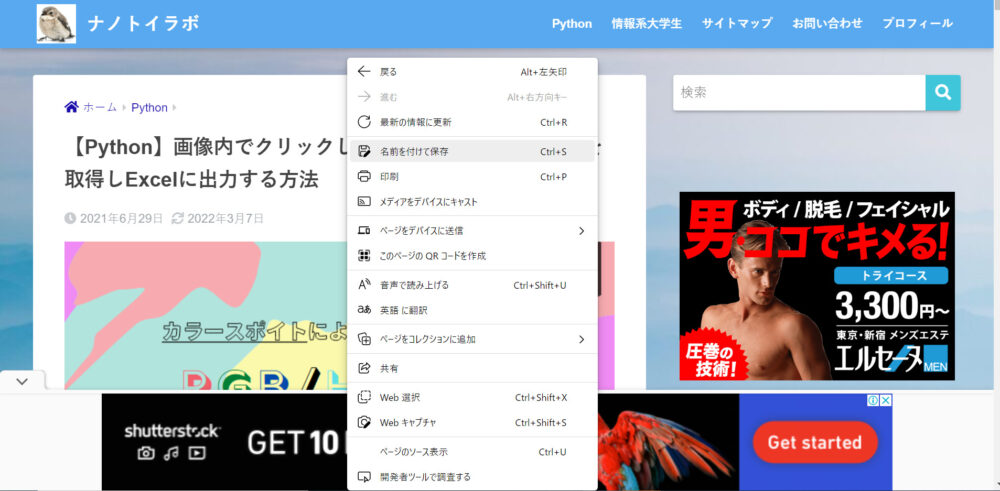
作成方法は下の画像の様に、サイトを右クリックして、名前を付けて保存をします。そして、PCにHTMLファイルを保存してください。
HTMLファイルをGoogleドライブにアップロード
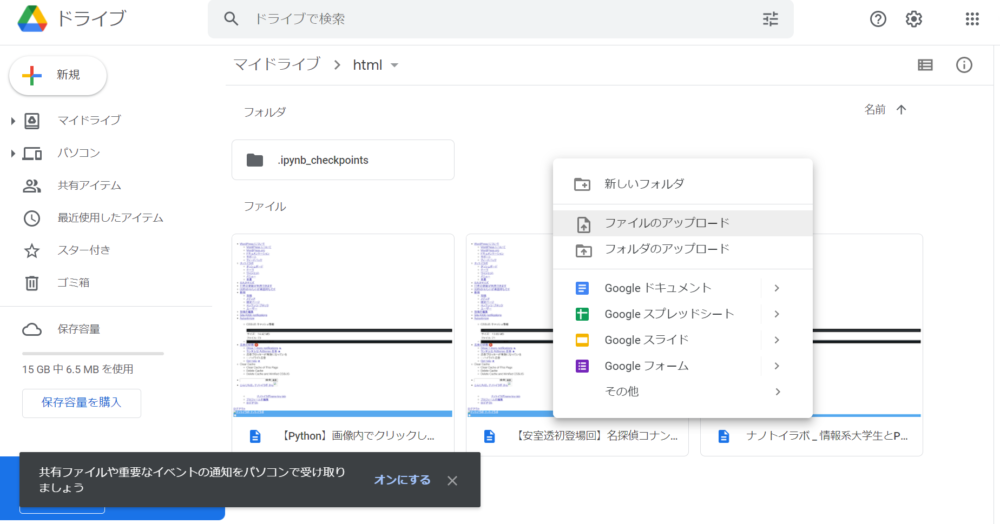
次に上で保存した、HTMLファイルをGoogleドライブにアップロードします。
下の画像の様にGoogleドライブで、ファイルをアップロードすれば大丈夫です。
Google Colaboratoryのマウント
今回はコードを実行するために、Google Colaboratoryを使います。Google Colaboratoryでは、Google ドライブのファイルにアクセスするためには、マウントする必要があります。
やり方はGoogle Colaboratoryで新規作成を行い、下記の通りにクリックすると、
「このノートブックに Google ドライブのファイルへのアクセスを許可しますか?」といったものが出てきます。
「Google ドライブに接続」を選択すれば、マウントが完了します。

マウントって何ですか???
マウントとは、認証といったアクセス許可のようなものです。
今回はGoogle ColaboratoryからGoogleドライブへのアクセスを許可させるといったイメージを持てば大丈夫!!
Pythonコードの作成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | from pathlib import Path #pathlibモジュールからPathオブジェクトを取り込む from bs4 import BeautifulSoup #bs4モジュールからBeautifulSoupオブジェクトを取り込む #作成したHTMLファイルからPathオブジェクトを作成して、変数tfileに入れる。 tfile = Path('/content/drive/MyDrive/html/【Python】画像内でクリックした箇所のRBG・HSVの値を取得しExcelに出力する方法 _ ナノトイラボ.html') #引数encodingに'utf-8'指定して、tfileから読み込んだテキストをttextに入れる。 ttext = tfile.read_text(encoding='utf-8') #ttextとhtml.parserからBeautifulSoupオブジェクトを作成して、soupに入れる。 soup = BeautifulSoup(ttext, 'html.parser') #soupから「title」タグを探し、titleに入れる。 title = soup.find('title') print(title.text) #【Python】画像内でクリックした箇所のRBG・HSVの値を取得しExcelに出力する方法 | ナノトイラボ |
サイトのタイトルである『【Python】画像内でクリックした箇所のRBG・HSVの値を取得しExcelに出力する方法』が無事出力されていますね!
URLから取り出す
上では、HTMLファイルを使用してきたが、実際のスプレイピングでは、プログラムでWebページを取得する必要があります。
今回はrequestsライブラリとget関数を使い、URLからHTMLを取り出して、サイトから要素を取り出します。
こちらの方法は先ほどのHTMLファイルから要素を取り出す方法より、手間いらず!!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import requests #requestsモジュールを取り込む from bs4 import BeautifulSoup #bs4モジュールからBeautifulSoupオブジェクトを取り込む #WebページのURLを変数urlに入れる。 url = 'https://nano-toy-lab.com/python/python-rgb-hsv-excel/' #変数urlが表すWebページを取得し、resに入れる。 res = requests.get(url) #resのテキストとhtml.parserを指定して、BeautifulSoupオブジェクトを作成して、soupに入れる。 soup = BeautifulSoup(res.text, 'html.parser') #soupから「title」タグを探し、titleに入れる。 title = soup.find('title') print(title.text) #【Python】画像内でクリックした箇所のRBG・HSVの値を取得しExcelに出力する方法 | ナノトイラボ |
HTMLファイルからタイトルを取り出す方法とあまりコードが変わらない??
変わっているところ6行目と8行目のコードがそれぞれ違うので、間違えないようにしよう!!
まとめ
最後まで読んでいただきありがとうございます。
今回はスプレイピングの基礎のWebサイトからタイトルの要素を取り出すのことをやりました。
せっかくなので、HTMLファイルからタイトルを取り出す方法と、URLから取り出す方法を試してみてください!
無料の説明会を有効活用しよう!
独学での学習は孤独感を感じやすく挫折してしまう初心者も多いです。また、参考書を購入しても全く読む気にならないという方も多いはずです。
それでも、なんとかPythonの勉強を行い、高スキルなエンジニアを目指したいという方は無料で受けられるオンライン説明会に参加してみることも一つの手です。
Pythonというプログラミング言語は機械学習の人気の高まりなどもあり、様々なスクールが無料説明会を開催しています。
その中でも「Freeks(フリークス)|業界初!10,780円のサブスク型プログラミングスクール」がオススメです。Pythonを効率よく学びたいという方はまずは適性を知るためにも無料説明会を利用しましょう。

